Method
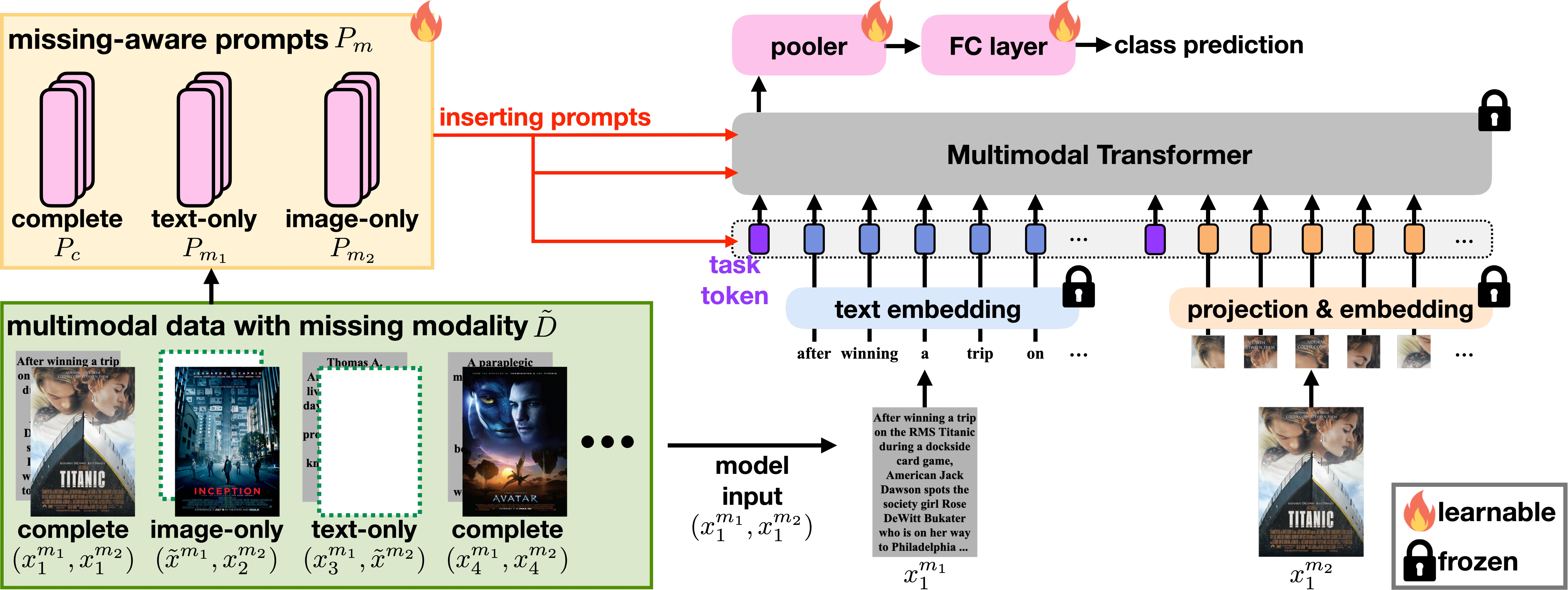
In this paper, we tackle two challenges in multimodal learning for visual recognition: 1) when missing-modality occurs either during training or testing in real-world situations; and 2) when the computation resources are not available to finetune on heavy transformer models. To this end, we propose to utilize prompt learning and mitigate the above two challenges together. Specifically, our modality-missing-aware prompts can be plugged into multimodal transformers to handle general missing-modality cases, while only requiring less than 1% learnable parameters compared to training the entire model. We further explore the effect of different prompt configurations and analyze the robustness to missing modality. Extensive experiments are conducted to show the effectiveness of our prompt learning framework that improves the performance under various missing-modality cases, while alleviating the requirement of heavy model re-training.
Results on the MM-IMDb, UPMC Food-101, Hateful Memes dataset with different missing rates under different missing-modality scenarios.